
What is DrizzleZip?
The answer to that is quite simple, let's say you have a folder with mixed files, some RAR, some ZIP, some 7z and some uncompressed files. Now, you decide for the sake of uniformity that you would like these files zipped up nice and pretty using 7z, ZIP, Gzip, Tar, Bzip, XZ or even TorrentZip techniques. Normally to do this you would have to jump through a lot of hoops. Enter DrizzleZip, simply select the folder which you wish to unify and click Process and in a matter of no time at all you will be left with a properly compressed directory.
DrizzleZip has native built in recursion techniques which ensures that every file, under every folder will be compressed exactly how you want it! DrizzleZip also supports file splitting (meaning that if you have a ROM folder (or other) lets say: MyZip.7z which contains MyZip1.bin, MyZip2.bin these files will be broken down and compressed on an individual basis (optional of course)) so you can easily separate your compressed files into multiple archives.
DrizzleZip also supports dragging a group of files, or entire folders (up to 1,000 folders) directly onto the application icon for command line processing.
DrizzleZip has TorrentZip support meaning you can TorrentZip files from any format (7z, Zip, RAR or even loose files) and they will be stripped down (the contents that is) and re-compressed as stable TorrentZip (0.9) files.
System Requirements
DrizzleZip does require Microsoft .NET framework 4.0 (full package) for proper operation as well as administrative rights to your PC (meaning it can only be ran using administrator credentials.
Notables
DrizzleZip is considered stable beta software so backing up your files prior to using the application is always suggested prior to any run. Should you encounter any errors while using the program please feel free to post your findings here so that I can assist with debugging and fixing the problem. Also, if you have ideals and/or suggestions on what we can do to make the application more suitable or more enhanced please let us know so that we may take care of it for you!
Screenshots
Main Interface
Password
Update v1.0.0.0 5-23-2013
DrizzleZip has made it out of the alpha stages and is ready for prime time deployment. I removed some of the redundant features and added in more sanity features such as command line processing better recursion techniques and a slew of error traps (if applicable.)
To run DrizzleZip as a command application simply type this into the command prompt:
drizzlezip.exe -convert -tzip "c:\files\to\zip"
This command will convert every file in c:\files\to\zip to the TorrentZip format.
Supported members are -zip -7z -tar -gz -xz -t7z -tzip
DrizzleZip is now multilingual you just add the XML to /Lang/ and restart DrizzleZip and it will detect the new language file, where you can select it from the Language tool member on the main GUI. Below is the English template which you can use to create your own language files; if you do create a language file please upload it to this forum so that others can get it, and so that I may include it pre-bundled on future releases.
<lang><menu><file value="File" /><neww value="New window" /><exit value="Exit" /><tool value="Tools" /><clch value="Clear cache data" /><vchd value="View cache data" /><lans value="Language" /><help value="Help" /></menu><itembar><fcompress value="Folder Compression" /><termoutpt value="Terminal Output" /><hlpcenter value="Help Center" /></itembar><directcontrol><title value="Directory Control" /><label value="Source Directory" /><vownr value="Verify ownership of directory/file" /><brose value="Browse" /></directcontrol><compresscontrol><title value="Compression Settings" /><ctype value="Compression Type" /><clvel value="Compression Level" /><cboxs value="Put each file in a seperate archive" /></compresscontrol><options><nerror value="Notify on error" /><bkerro value="Break current operation" /><lgcont value="Log And Continue" /><enflbk value="Enable file backups" /><pmptin value="Prompt user for input" /><useinc value="Use incremental backups" /><ntflow value="Notify on low space waring" /></options><appcontrol><pausctrl value="Pause" alt="Resume" /><prcejobf value="Process Job" alt="Cancel" /><loggnopt value="Logging Options" /><svtoterm value="Save terminal to logfile" /><btnsavas value="Save As" /><ovrallop value="Overall Operation" /><btnclrtl value="Clear Terminal" /></appcontrol></lang>
Recently I had the need to obtain tons of data (as I am creating my own video gaming frontend (no, it's not for new systems; it is for old computers to play DOS games on.)) but there seemed to be a lack of tools out there for us software developers to use. So, my solution was to just simply make my own damned scraper that obtains detailed information from MobyGames. So, here I am after a day and a half of creating this scraper solution and am sharing it with the community in the hopes that I may save some other developer out there the headache and torture of doing this themselves.
The only functionality that I left out of the scraper is the obtaining of images (as most of MobyGames images are sub-par at best anyhow) and all I care about is the detailed data and don't want to waste any of their bandwidth obtaining said images.
The Dynamic Link Library
Using the library is fairly simple and a straight forward process. What I usually do is declare a global List<MobyGamesSearchResult> that is populated later on in the code. The reason that I declare a global is so that I can easily obtain the name of the game, and the MobyGames.com URL for the application URL (later on in the code examples it will become clearer what I mean.)
Setting up your methods
using MobySharp;
using MobySharp.Methods;
public partial class Form1 : Form
{
List<MobyGamesSearchResult> _gameList = new List<MobyGamesSearchResult>();
.....
Now that you have declared all of your variables that you will be using throughout the application we can safely populate our results list by calling a search function.
_gameList = new MobyScraper().SearchMoby(searchString);
if (_gameList != null)
foreach (var results in _gameList)
{
listBox1.Items.Add(results.Name);
}
Where searchString is equal to the name of the game you are looking for (ie DOOM II). You will notice that I also trap a null search result in the code above; as there is currently no method implemented of converting a null search (ie no games found.)
So, now that we have our _gameList populated and have listed all of the search names into a nice tidy listbox we can continue our code as seen whenever the user changes the listbox1 index.
foreach (var result in _gameList)
{
if (result.Name == (string)listBox1.SelectedItem)
{
var entry = new MobyScraper().GameInformation(result.Url);
labelName.Text = (string)listBox1.SelectedItem;
labelPublisher.Text = entry.Publisher;
labelReleaseDate.Text = entry.ReleaseDate;
labelDeveloper.Text = entry.Developer;
labelPlatform.Text = entry.Platform;
labelGenre.Text = entry.Genre;
labelPerspective.Text = entry.Perspective;
richTextBox1.Text = entry.Description;
richTextBox2.Text = entry.AlternateTitles;
return;
}
}
So, as you can see by the code above we first get a search list of all available titles; and an URL is assigned to each title. After we have made a game selection we cross reference the title name against the selected game and if a match is found we extract the URL and then create a new GameInformation object which will contain all of the data on said game.
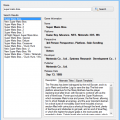
The Example Application Showing Data
Posted Image
Anyhow, I hope some of my fellow third party developers get some use out of this; I have attached a sample application as well as the stand alone DLL file in this post.

Dat-O-Matic dat file parsing system which I created for a very special project that I am working on; I figured it would save some of the developers out there several hours of leg work creating their own. Currently it parses UTF/Text dat files found on http://datomatic.no-intro.org/ I plan on adding functionality of allowing it to parse XML/Text type DAT files at some point in time. Without further delay here is how you use this bad boy.
Include a reference
using DatProcessor;
Initialize the code
var myMethod = new DatFileProcessor();
var myGames = myMethod.ProcessFile(@"c:\path\to\my\datfile.dat");
This will read your DAT file into an object type that will be held much like a list type, and here is a quick and dirty way to loop through all of the data that can be found from that DAT file.
Looping through games
foreach (var myGame in myGames)
{
Console.WriteLine(myGame.Index);
Console.WriteLine(myGame.Name);
Console.WriteLine(myGame.RomCrc);
Console.WriteLine(myGame.RomMd5);
Console.WriteLine(myGame.RomName);
Console.WriteLine(myGame.RomSha);
Console.WriteLine(myGame.RomSize);
Console.WriteLine(myGame.Serial);
}
Overview - The Layout of a DAT
game (
name "Circus Attractions (Europe) (Compilation - Milestones)"
description "Circus Attractions (Europe) (Compilation - Milestones)"
rom ( name "Circus Attractions (Europe) (Compilation - Milestones).ipf" size 928295 crc 83BA36E2 md5 1B54BFAA5325EC1D654BF035299B0CCF sha1 516672412F3532F823088FD71A669D30E226D5CA )
)
Index - Stores the line number within the file where the game has been located
Name - Stores the proper name of the game found in line #2 above
RomCrc - Stores the CRC value of the rom found in line #3
RomSha - Stores the SHA1 value of the rom found in line #3
RomMd5 - Stores the MD5 value of the rom found in line #3
RomName - Stores the literal name of the rom found in line #3
RomSize - Stores the size of the current rom found in line #3
RomSerial - When applicable this will store the value of a games serial (typically found in line #3/#4)
Anyways ladies and gents, I just wanted to spread my works for any of our brilliant software developers out there who need a quick and simple way of parsing DAT files; I will add a searching algorithm in later as well. Thanks everyone!
A utility designed for simple ROM matching against HyperSpin databases.
Introduction:
Okay, I'm back again this time with a brand new invention (no not a play on Vanilla Ice) that might help my fellow gamers setup their HyperSpin ROMS more efficiently. Now for those of you whom don't know me my name is Ronald or "rain" here on the forums and I am a computer software designer whom programs applications designed mostly for video gaming. I have tried a lot of the other systems out there and I am not sure about you guys but I personally don't feel safe using bulk renamers (as they tend to do more harm than good, and promote an all around sense of laziness.) So, I rebuilt an application that I orignally programmed back in 2010 that help me setup my HyperSpin setup (consisting of over 92 seperate systems) HyperMatch allows you to audit your systems individually to find missing ROM files (as they pertain to the HyperSpin databases), it then allows you to run a fuzzy match on the missing file, and then you can either remove the missing game from you HyperSpin database, rename a file or disregard it all together. I have used this program for a few years now, but just now got around to coding it for HyperSpin 2.0 databases.
Setting Up HyperMatch:
HyperMatch must be ran from the HyperSpin root folder (as it reads your database & settings files), so whenever you download the application make sure you unzip it to the correct folder otherwise HyperMatch will not work.
The User Interface:
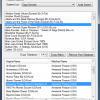
Whenever you first open HyperMatch you will see a basic window that displays a list of the systems it has detected were in your HyperSpin installation, from this interface you can scan a system, rename ROM files, delete missing ROM files from your system database. (see fig 1)
Using the drop down menu you should then select a system in which you would like to audit, once you have done so you will then click on the button labeled 'Audit System.' After a few moments (depending upon the size of your database) you will then see a list of missing ROM files appear in the top window. (see fig 2)
Once your missing ROM files list has been populated you can then click on an item and choose which action you wish to perform on the file such as Fuzzy Match or Remove From Database. If you would like to run a name search on the missing file you can than set the Fuzzy Match tolerance to a desired percentile (I personally use 0.4), and then click the button labeled 'Fuzzy Match.' After which your ROM folder is scanned for a list of potential ROM's that might be misnamed. (see fig 3)
Once the list of potential matches has been populated you can then click on the ROM name from the bottom list and select the button labeled 'Rename Selected.' Once you have done so you will then be asked for confirmation, provided you choose yes than the file will be renamed to the new database compliant name. (see fig 4 & 5)
The same process as above is used whenever removing files from a HyperSpin database.
A Word of Caution:
HyperMatch was not designed to handle MAME renaming, please do not use this tool in attempt to make your MAME database compliant, there are much better tools suited for that such as ClrMamePro. Using this application on MAME will 100% screw it up, so never, ever do it!


